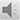

SPSS:缺失值填补——多重填补。
一、案例介绍
此处仍以缺失情况基本分析(链接)一文中生成的缺失数据为例。调查了33名研究对象的性别(gender)、年龄(age)和某生化指标(X),分析性别和年龄对生化指标浓度是否有影响?人为生成一个有缺失值(生化指标缺失10个个案,并且都是在高年龄组缺失)的数据(见图1),然后再进行填补分析。

图1
二、回归算法填补
(一) 软件操作
选择“分析”—“多重插补”—“插补缺失数据”(图2)。
图2
将用于缺失值填补的变量选入“模型中的变量”,“插补数”可以根据情况进行设置,默认为“5”。“插补数据的位置”中可以对插补后的数据集命名(图3)。

图3
“方法”模块中,默认“自动”,也可以自定义选择,如数据集较大时可以使用蒙特卡洛模拟(图4)。

图4
“约束”模块中,可以对填补模型加以微调。“重新扫描数据”可以在“变量摘要”中检查变量缺失情况;“定义约束”中可以设置某些变量只用于预测或只用于插补(图5)。

图5
(二) 效果比较
通过多种填补后可见生成了一个名称为“多重填补”的新数据集。
该数据集中包括1个原始数据和5个新生成的数据。在数据集的右上方点击可以依次查看每个数据集的情况。此时菜单中很多统计分析过程的图标也会改变为,如交叉表、线性回归等都是如此,表示该过程可以直接使用多重填补后的数据进行分析。
通过对多重填补后的数据集进行分析,只要图表为的数据集均会自动利用该数据集进行计算。通过线性回归分析结果见图6。

图6
将多重填补的结果和其他方法的结果对比见表1。

表1
通过对比可知,多重填补结果只比“序列平均值”效果好,比其他几种方法似乎还要差一些,这说明多重填补算法虽然在理论上比较完善,但实际应用过程中有时还存在许多问题。这再次提示缺失值处理是一个非常复杂的过程,需要结合专业、经验、方法学加以综合考虑,尤其是不要轻信单一填补后的结果,有时根据专业知识人工填补甚至不填补的结果反而更接近真实情况。