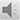

高质量的数据是进行统计分析的前提以及分析结果可靠性的保障。不论是原始数据还是公共数据,或多或少会存在一些质量问题。为了满足数据分析和数据挖掘的实际需要,需要对数据进行预处理。预处理是指在分析数据之前对数据源进行审核和判断,按照科学的方法尽可能地降低噪声数据对分析结果的影响,这是必不可少的环节。而缺失值的判断和处理是数据质量核查过程中的重要内容之一。
一、数据缺失的产生原因
数据缺失的产生原因很多,主要包括以下4种原因。
(一) 非专项调查.
一般专项调查具有严谨的科研设计、严格的数据采集和质量控制过程,从而尽可能避免数据缺失的问题。而非专项调查,如医院病案系统数据等,往往数据缺失现象比较普遍。
(二) 数据储存不当或出现故障.
采集数据的设备、存储介质或传输媒体等出现故障而造成的数据丢失。
(三) 敏感性问题.
在涉及如家庭人均收入、个人性行为、药品滥用等敏感性问题的问卷调查过程中,研究对象可能出于各种原因不愿意提供相关信息,从而造成数据缺失现象。
(四) 暂时无法获取的信息.
例如某种产品的收益等具有滞后效应,若要在收集到此类信息之前进行数据分析,则容易出现缺失值。
二、数据缺失类型
根据数据缺失的性质,可分为完全随机缺失、随机缺失和非随机缺失3种类型。
(一) 完全随机缺失.
完全随机缺失(missing completely at random,MCAR)是指缺失现象的发生完全随机产生,与自身或其他变量的取值无关。评估数据是否是MCAR,可通过比较缺失组和非缺失组目标变量的差异是否有统计学意义来判断,但实际应用中符合完全随机缺少的情况很少,因此判断MCAR一定要慎重。
MCAR是数据缺失类型中最易处理的一种。可以直接将缺失值删除,不会造成估计偏差,但会损失一些信息。也可以考虑采用合适的填补方法对缺失值进行填补,以充分利用样本信息。
(二) 随机缺失.
随机缺失(missing at random,MAR)是指数据缺失的发生与其他无缺失值变量的取值有关。如调查器官移植受者术后感染发生情况时,痰培养结果出现数据缺失,但发现缺失多来源于病情危重者,主要原因是病情危重者痰标本采集较为困难。这种情况下,缺失值不仅会损失信息,还可能会导致分析结果发生偏差。
当数据缺失是MAR时,直接将缺失值删除或者简单地用平均值填补并不合适,应当采用更复杂的算法对缺失值进行估计。或者评价过缺失值对分析结果的影响程度后,采取相应的措施进行处理,以得到客观准确的分析结果。MAR比MCAR要严重,但也更常见。
(三) 非随机缺失.
非随机缺失(missing at non-random,MANR)是指数据的缺失不仅和其他变量的取值有关,也和自身取值有关。例如,在调查收入时,由于高收入人群可能出于各种原因不愿意提供家庭年收入,而造成数据缺失。
MANR是数据缺失中最糟糕的一种情况。对于这种情况,缺失值分析模型基本上无能为力,只能做非常粗略的估计。因此,在部分文献中MANR也被称为不可忽略的缺失。
三、数据缺失的处理策略
(一) 不处理.
不处理就是直接对包含空值的数据集进行分析。但是很多统计分析方法在分析过程中会默认对缺失值个案进行成对删除。“不处理”策略可以灵活使用,如在对单因素分析有统计学意义的变量进行多因素回归分析的过程中,单因素分析时可采取不处理策略,而多因素分析时可对缺失值进行相应的处理。
(二) 删除法.
删除法在删除数据的过程中会减少原始数据的信息量。当缺失值数量占比非常小时,简便易行、简单有效;而当缺失数据占比较大时,尤其是缺失数据为非随机分布时,这种方法可能发生偏倚,甚至可能得出错误的结论。因此,通常缺失值非常少时,采用此方法,主要包括以下3种。
1. 按分析删除.
按分析删除(exclude cases analysis by analysis)即当某次分析中具体用到的变量有缺失值时,将相应的案例去除,这是多数情况下的默认处理方式。属于成列删除(listwise)的范畴。
2. 按列表删除.
按列表删除(exclude cases listwise)即当一次选择多个变量进行同类分析时,只要被分析的变量有缺失值,就在所有分析中将该案例去除。也属于成列删除(listwise)的范畴。
3. 成对删除.
成对删除(pairwise deletion),也称配对删除,适用于两两配对的变量。当某种信息在其中一个配对变量缺失时,则在进行这对配对变量的统计量计算时把含有缺失值的数据删除,而在计算其他变量的统计量时不受影响。
(三) 填补法
填补法的主要原则是以最可能的值来填补缺失值,这比直接删除不完全样本所产生的信息丢失要少。在数据挖掘和分析中,通常面对的是大型的数据库,包含的变量较多,因为一个变量值的缺失而放弃大量的其它变量是对信息的极大浪费。填补法主要包括人工插补、简单填补和复杂填补。
1. 人工插补.
人工插补(filling manually)是指人工根据明确的专业信息提示填补数据。该方法较为费时,且需要较高的专业素养,一般适用于小范围的数据填补。当数据规模较大、空值较多时,该方法不太可取。
2. 简单填补.
简单填补是指根据简单的算法或规则对数据进行填补。其优点是原理简单、易于操作,而缺点是不考虑缺失值的变异性,容易造成偏差,一般不建议用于主要分析。简单填补主要有以下几种常见方法。
(1) 平均值填补.
根据缺失数据的类型进行填补,若缺失值为数值型,则用该变量平均值填补;若为非数值型,则用该变量出现频率最高的水平填补。
(2) 条件平均值填补.
条件平均值填补(conditional mean imputation, CMI)与平均值填补类似,但更为精确。是指从与该对象具有相同属性的子对象中求得平均值或最高频率水平进行填补。例如,对血压缺失数据进行填补,可根据缺失值所在研究对象的年龄段(或性别)找到相同年龄段(性别)研究对象血压的平均值进行填补,比直接用全样本的平均值替换更科学准确。
(3) 热卡填补.
热卡填补(Hot deck imputation, HI)也称邻近填补法,是指在整个数据集中搜索一个与缺失值最相似的值进行填补。该方法利用了数据间的关系进行填补,虽然概念较为简单,但是难以定义数据相似的标准,受主观因素影响较大。
(4) K平均值法.
K平均值法(K-means clustering)是指先根据欧式距离或相关分析确定与缺失数据样本最近的K个样本,使用K个值加权平均估计该样本的缺失数据。根据数据类型的不同,距离度量也不相同。对于连续变量,常用欧氏距离、曼哈顿距离或余弦距离;对于分类变量,常用汉明(Hamming)距离。K平均值法在分析大型数据集时非常耗时。
(5) 其他方法.
还有一些简单填补方法,包括基线观测结转(baseline observation carried forward, BOCF)、末次观测结转(last observation carried forward, LOCF)、最差观测结转( worst observation carried forward, WOCF)。BOCF是指使用缺失变量的基线值填补其后所有缺失值。该方法较适用于慢性疼痛类疾病,受试者的数据缺失可能是由于疼痛等结局指标回到了基线水平,而受试者因无效退出试验,发生失访导致数据趋势。LOCF法是指采用缺失值前一次访视的观测值填补其后所有缺失值,通常所得效应估计趋向于保守。WOCF法是指用受试者观测数据中的最差的观测值去填补缺失,该方法是非常保守,通常用于敏感性分析。
3. 复杂填补
(1) 回归算法.
回归算法填补是指以所有纳入变量为自变量,以存在缺失值的变量为因变量建立回归方程,在得到回归方程后,利用该方程对因变量相应的缺失值进行填补。具体的填补数值为回归预测值加上任意一个回归残差,使它更接近实际情况。若存在多个缺失变量则为它们分别建立回归方程,依次进行预测和填补。
(2) 期望最大法.
期望最大(Expectation maximization,EM)法是一种迭代算法,主要用来求后验分布的最大似然估计值。该算法在缺失值的估计上非常有效。每次迭代由两步组成:E步求期望,M步则将随机参数进行极大化。在运算时,首先给该变量一个初始值,然后求出模型中的各个参数估计值(M步),随后利用新估计出的模型对该随机变量值进行估计(E步)。如此反复迭代,直至收敛。据大量实践,人们发现EM法可以很好地处理大多数缺失值问题,是一个非常稳健的缺失值填补算法。
(3) 多重填补.
上述填补法对每一个缺失值都只给出一个填补值的估计,其准确性难免受到质疑。而多重填补(Multiple Imputation, MI)考虑到数据填补的不确定性,可以产生若干个完整的填补后数据集,使结果更为可靠。MI过程大致分3步:
(1) 插补:为每个缺失值产生一系列可能的填补值。具体的填补算法可能是回归算法,也可能是马尔科夫链蒙特卡洛模拟(Markov Chain Monte Carlo Simulation, MCMC)。这些数值反映了缺失数据未知真实值的不确定性,而每一个值都会被用于填补,从而产生若干个完整的填补后的数据集。
(2) 分析:分别对每一个完整数据集进行预计的统计分析。
(3) 合并:对来自各个填补数据集的分析结果进行综合,产生最终的统计推断。
(四) 虚拟变量法.
虚拟变量法也称特殊值填充,常用于非计量资料。如在单因素或多因素回归分析过程中,可将缺失变量指定为“未知”或“其他”类别,以满足数据分析的需要。特别需要注意的是,虚拟变量对应的效应量(如OR值、HR值等)并无实际的专业意义。
本文主要内容总结见图1。
图 1
四、数据缺失处理的注意事项
(一) 避免缺失值的产生最为关键.
无论何种数据填补方法,均是对原始数据的一种猜测和估计,其效果均不如原始数据。因此,避免缺失值产生的最直接和最有效的办法是在研究设计和数据收集过程中做好质量控制。
(二) 并不是所有数据都可以填补.
一些特殊类型的数据和特定研究设计的数据最好不要使用填补法,举例包括:
反应个体属性的数据,如性别、血型等。此类数据缺失最好回溯原始数据尽可能补全。 重复测量设计研究中的某次测量数据。此类数据缺失,不建议替补,一般建议选择允许缺失值存在的替代分析方法,如使用广义估计方程(GEEs)或混合线性模型。 变异很大的数据。如一些传染病的发病率在不同人群和地区中差异很大,很难通过模型估计其真实值。 (三) 敏感性分析必不可少
无论是删除缺失值还是填补法均是对真实数据的有偏估计。不要轻信单一处理方法的结果,尤其是当样本量较小或者缺失值比例较大时,需要通过不同方法处理缺失值数据,并比较不同分析结果的差异。若分析的结果较为稳定,那么不同方法结果虽然会有微小差别,但不会有质的差异,可做出相应的统计判断;若不同分析方法的结果差异较大,甚至相反,此时须进一步详细研究,慎重下结论。
(四) 并无“最优”办法.
尽管目前关于缺失值的处理有多种方法,但是很难说哪种方法最优,因为不同方法均有各自的适用条件,应根据数据缺失的性质、临床研究设计的类型、变量属性、临床意义等综合选择恰当的填补方法。
虽然MI法在理论上比较完善,但是在应用中也存在诸多问题。首先,MI法建立在数据缺失为MAR,对于非MAR的数据缺失无法处理。其次,在大多数MI方法中,须先根据某种概率分布假设产生相应的填补数据,这显然使该方法的应用受到限制,且其运算过程趋于复杂,对某些复杂的缺失问题需要进行MCMC。最后,在多数实际问题中,研究者发现MI法与EM法比较,填补效果并无差异,而MI法运算过程和资源消耗又远大于EM法(原因在于EM法可以直接从不完全数据中得到参数的最大似然估计,而不需要像MI法那样进行反复模拟来寻找最佳的参数分布)。
此外,很多专业数据挖掘人员通过他们对行业的理解,手动对缺失值进行插补的效果可能比这些方法更好。